Levels of Abstraction
15 min read
Learning Outcomes
- Understand the motivation for different programming paradigms: from abstract machine operation to human-understandable and composable programs
- Understand the difference between syntaxThe set of rules that defines the combinations of symbols that are considered to be correctly structured statements or expressions in a computer language. (the textual symbols and grammatical rules of a program) and semanticsThe processes a computer follows when executing a program in a given language. (the meaning of what is computed)
- Understand that there are different models of computation upon which different programming languages are based, including machine models such as Turing MachinesA model of computation based on a hypothetical machine reading or writing instructions on a tape, which decides how to proceed based on the symbols it reads from the tape. and von Neumann architecture, and the Lambda CalculusA model of computation based on mathematical functions proposed by Alonzo Church in the 1930s. based on mathematical functions
Syntax versus Semantics
As a branch of Computer Science, the theory and practice of programming has grown from a very practical need: to create tools to help us get computers to perform useful and often complex tasks. Programming languages are tools that are designed and built by people to make life easier in this endeavour. Furthermore, they are rapidly evolving tools that have grown in subtlety and complexity over the many decades to take advantage of changing computer hardware and to take advantage of different ways to model computation.
An important distinction to make when considering different programming languages is between syntaxThe set of rules that defines the combinations of symbols that are considered to be correctly structured statements or expressions in a computer language. and semanticsThe processes a computer follows when executing a program in a given language. . The syntaxThe set of rules that defines the combinations of symbols that are considered to be correctly structured statements or expressions in a computer language. of a programming language is the set of symbols and rules for combining them (the grammar) into a correctly structured program. These rules are often arbitrary and chosen for historical reasons, ease of implementation or even aesthetics. An example of a syntactic design choice is the use of indentation to denote block structure or symbols such as “BEGIN” and “END” or “{” and “}”.
Example: functions in Python and C that are syntactically different, but semantically identical:
# python code
def sumTo(n):
sum = 0
i = 0
while i < n:
sum += i
i += 1
return sum
// C code:
int sumTo(int n) {
int sum = 0;
for(int i = 0; i < n; i++) {
sum += i;
}
return sum;
}
By contrast, the “semanticsThe processes a computer follows when executing a program in a given language. ” of a programming language relate to the meaning of a program: how does it structure data? How does it execute or evaluate?
In this course we will certainly be studying the syntaxThe set of rules that defines the combinations of symbols that are considered to be correctly structured statements or expressions in a computer language. of the different languages we encounter. It is necessary to understand syntaxThe set of rules that defines the combinations of symbols that are considered to be correctly structured statements or expressions in a computer language. in order to correctly compose programs that a compiler or interpreter can make sense of. The syntactic choices made by language designers are also often interesting in their own right and can have significant impact on the ease with which we can create or read programs. However, arguably the more profound learning outcome from this course should be an appreciation for the semanticsThe processes a computer follows when executing a program in a given language. of programming and how different languages lend themselves to fundamentally different approaches to programming, with different abstractions for modelling problems and different ways of executing and evaluating. Hence, we will be considering several languages that support quite different programming paradigms.
For example, as we move forward we will see that C programs vary from the underlying machine language mostly syntactically. C abstracts certain details and particulars of the machine architecture and has much more efficient syntaxThe set of rules that defines the combinations of symbols that are considered to be correctly structured statements or expressions in a computer language. than Assembly language, but the semanticsThe processes a computer follows when executing a program in a given language. of C are not so far removed from Assembly - especially modern assembly that supports procedures and conveniences for dealing with arrays.
By contrast, Haskell and MiniZinc (which we will be exploring in the second half of this course) represent quite different paradigms where the underlying machine architecture, and even the mode of execution, is significantly abstracted away. MiniZinc, in particular, is completely declarativeDeclarative languages focus on declaring what a procedure (or function) should do rather than how it should do it. in the sense that the programmer’s job is to define and model the constraints of a problem. The approach to finding the solution, in fact any algorithmic details, is completely hidden.
One other important concept that we try to convey in this course is that while some languages are engineered to support particular paradigms (such as functionalFunctional languages are built around the concept of composable functions. Such languages support higher-order functions which can take other functions as arguments or return new functions as their result, following the rules of the Lambda Calculus. programming or logic programming), the ideas can be brought to many different programming languages. For example, we begin learning about functionalFunctional languages are built around the concept of composable functions. Such languages support higher-order functions which can take other functions as arguments or return new functions as their result, following the rules of the Lambda Calculus. programming in JavaScript (actually TypeScript and ECMAScript 2017), and we will demonstrate that functionalFunctional languages are built around the concept of composable functions. Such languages support higher-order functions which can take other functions as arguments or return new functions as their result, following the rules of the Lambda Calculus. programming style is not only possible in this language, but brings with it a number of benefits.
Later, we will pivot from JavaScript (briefly) to PureScript, a Haskell-like language that compiles to JavaScript. We will see that, while PureScript syntaxThe set of rules that defines the combinations of symbols that are considered to be correctly structured statements or expressions in a computer language. is very different to JavaScript, the JavaScript generated by the PureScript compiler is not so different to the way we implemented functionalFunctional languages are built around the concept of composable functions. Such languages support higher-order functions which can take other functions as arguments or return new functions as their result, following the rules of the Lambda Calculus. paradigms manually in JavaScript.
Then we will dive a little more deeply into a language that more completely “buys into” the functionalFunctional languages are built around the concept of composable functions. Such languages support higher-order functions which can take other functions as arguments or return new functions as their result, following the rules of the Lambda Calculus. paradigm: Haskell. As well as having a syntaxThe set of rules that defines the combinations of symbols that are considered to be correctly structured statements or expressions in a computer language. that makes functionalFunctional languages are built around the concept of composable functions. Such languages support higher-order functions which can take other functions as arguments or return new functions as their result, following the rules of the Lambda Calculus. programming very clean, the Haskell compiler strictly enforces purity and makes the interesting choice of being lazy by default.
In summary, the languages we will study (in varying degrees of depth) will be Assembly, C/C++, JavaScript (ES2017 and TypeScript), PureScript, Haskell and MiniZinc, with JavaScript/TypeScript and Haskell being the main languages explored in problem sets and assignments. Thus, this course will be a tour through programming paradigms that represent different levels of abstraction from the underlying machine architecture. To begin, we spend just a little time at the level of least abstraction: the hardware itself.
The Machine Level
Conceptually, modern computer architecture deviates little from the von Neumann modelA model of computation which is the basis for most modern computer architectures. Proposed by John von Neumann in 1945.
proposed in 1945 by Hungarian-American computer scientist John von Neumann.
The von Neumann architecture was among the first to unify the concepts of data and programs. That is, in a von Neumann architecture, a program is just data that can be loaded into memory. A program is a list of instructions that read data from memory, manipulate it, and then write it back to memory. This is much more flexible than previous computer designs which had stored the programs separately in a fixed (read-only) manner.
The classic von Neumann modelA model of computation which is the basis for most modern computer architectures. Proposed by John von Neumann in 1945. looks like so:
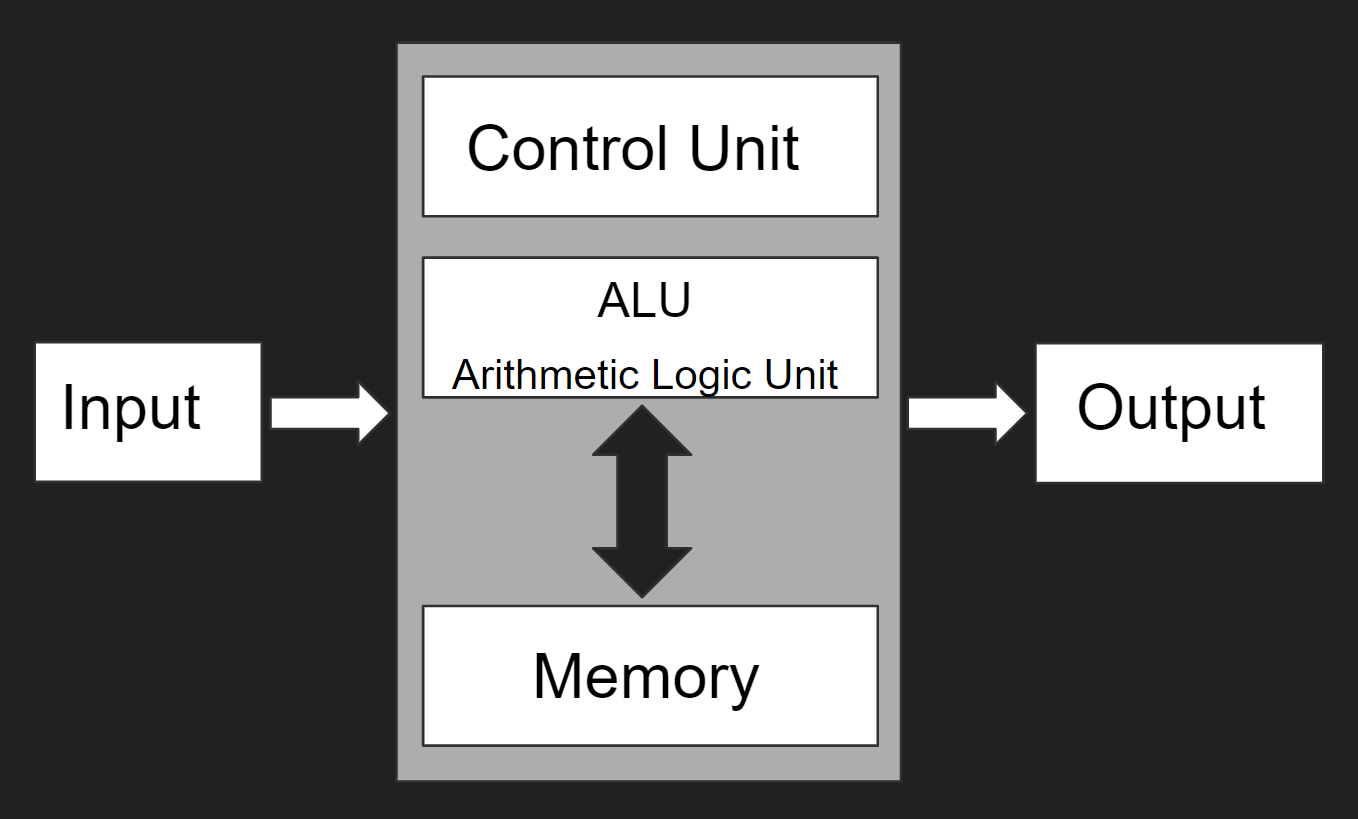
At a high level, standard modern computer architecture still fits within this model:
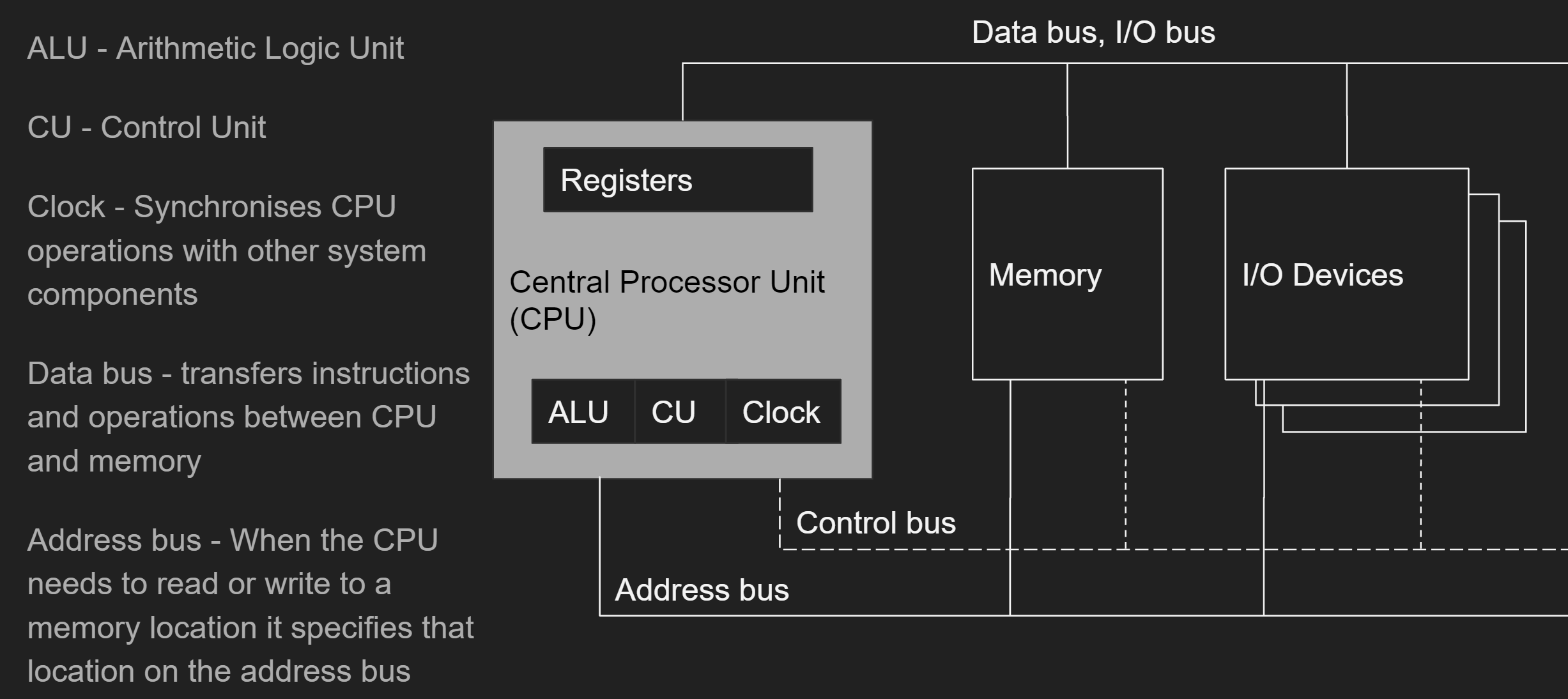
Programs run on an x86 machine according to the Instruction Execution Cycle:
- CPU fetches instruction from instruction queue, increments instruction pointer
- CPU decodes instruction and decides if it has operands
- If necessary, CPU fetches operands from registers or memory
- CPU executes the instruction
- If necessary, CPU stores result, sets status flags, etc.
Registers are locations on the CPU with very low-latency access due to their physical proximity to the execution engine. Modern x86 processors also have 2 or 3 levels of cache memory physically on-board the CPU. Accessing cache memory is slower than accessing registers (with all sorts of very complicated special cases) but still many times faster than accessing main memory. The CPU handles the movement of instructions and data between levels of cache memory and main memory automatically, cleverly and—for the most part—transparently. To cut a long story short, it can be very difficult to predict how long a particular memory access will take. Probably, accessing small amounts of memory repeatedly will be cached at a high level and therefore fast.
Other Models of Computation
Turing MachinesA model of computation based on a hypothetical machine reading or writing instructions on a tape, which decides how to proceed based on the symbols it reads from the tape. are a conceptual model of computation based on a physical analogy of tapes being written to and read from as they feed through a machine. The operations written on the tape determine the machine’s operation. The von Neumann modelA model of computation which is the basis for most modern computer architectures. Proposed by John von Neumann in 1945. of computation has in common with Turing MachinesA model of computation based on a hypothetical machine reading or writing instructions on a tape, which decides how to proceed based on the symbols it reads from the tape. that it follows an imperativeImperative programs are a sequence of statements that change a program’s state. This is probably the dominant paradigm for programming languages today. Languages from Assembly to Python are built around this concept and most modern languages still allow you to program in this style. paradigm of sequential instruction execution, but it is a practical model upon which most modern computers base their architecture.
There are other models of computation that are also useful. In particular, we will look at the Lambda CalculusA model of computation based on mathematical functions proposed by Alonzo Church in the 1930s. , which was roughly a contemporary of these other models but based on mathematical functions, their application and composition. We will see that while imperativeImperative programs are a sequence of statements that change a program’s state. This is probably the dominant paradigm for programming languages today. Languages from Assembly to Python are built around this concept and most modern languages still allow you to program in this style. programming languages are roughly abstractions of machine architecture, functionalFunctional languages are built around the concept of composable functions. Such languages support higher-order functions which can take other functions as arguments or return new functions as their result, following the rules of the Lambda Calculus. programming languages provide an alternative abstraction built upon the rules of the lambda calculusA model of computation based on mathematical functions proposed by Alonzo Church in the 1930s. .
Alternative Abstractions
Humans think about programs in a different way from machines. Machines can read thousands or millions of instructions per second and execute them tirelessly and with precision. Humans need to understand programs at a higher level and relate the elements of the program back to the semanticsThe processes a computer follows when executing a program in a given language. of the task and the ultimate goal. There is a clear and overwhelmingly agreed-upon need to create human-readable and writable languages that abstract away the details of the underlying computation into chunks that people can reason about. However, there are many ways to create these abstractions.
Comparing the Dominant Programming Paradigms
First, some definitions that help to describe the different families of programming languages that we will be considering in this course. It is assumed that the reader already has experience with the first three paradigms (imperativeImperative programs are a sequence of statements that change a program’s state. This is probably the dominant paradigm for programming languages today. Languages from Assembly to Python are built around this concept and most modern languages still allow you to program in this style. , proceduralProcedural languages are basically imperative in nature, but add the concept of named procedures, i.e. named subroutines that may be invoked from elsewhere in the program, with parameterised variables that may be passed in. and object-orientedObject-oriented languages are built around the concept of objects where an object captures the set of data (state) and behaviours (methods) associated with entities in the system. ) since these are taught in most introductory programming courses. The rest are discussed further in later chapters in these notes.
- ImperativeImperative programs are a sequence of statements that change a program’s state. This is probably the dominant paradigm for programming languages today. Languages from Assembly to Python are built around this concept and most modern languages still allow you to program in this style. programs are a sequence of statements that change a program’s state. They follow the Turing machineA model of computation based on a hypothetical machine reading or writing instructions on a tape, which decides how to proceed based on the symbols it reads from the tape. model described above. This is probably the dominant paradigm for programming languages today. Languages from Assembly to Python are built around this concept and most modern languages still allow you to program in this style.
- ProceduralProcedural languages are basically imperative in nature, but add the concept of named procedures, i.e. named subroutines that may be invoked from elsewhere in the program, with parameterised variables that may be passed in. languages are basically imperativeImperative programs are a sequence of statements that change a program’s state. This is probably the dominant paradigm for programming languages today. Languages from Assembly to Python are built around this concept and most modern languages still allow you to program in this style. in nature, but add the concept of named procedures, i.e. named subroutines that may be invoked from elsewhere in the program, with parameterised variables that may be passed in. The result of the procedure may be returned as an explicit return value, or the procedure may mutate (change) the value of variables referenced elsewhere in the program (such a mutation is called a side effect). Again, most modern languages support the definition of such procedures. Sometimes, the term function is used synonymously with procedure. Some languages (e.g. Pascal) make a distinction between procedures that mutate state without an explicit return value, while a function has an explicit return value. Note that the latter is closer to the definition of function in mathematics.
- Object-orientedObject-oriented languages are built around the concept of objects where an object captures the set of data (state) and behaviours (methods) associated with entities in the system. languages are built around the concept of objects, where an object captures the set of data (state) and behaviours (methods) associated with entities in the system. We assume most readers have already studied the basics of object-orientedObject-oriented languages are built around the concept of objects where an object captures the set of data (state) and behaviours (methods) associated with entities in the system. programming, such as defining classes of objects, inheritance and encapsulation.
- DeclarativeDeclarative languages focus on declaring what a procedure (or function) should do rather than how it should do it.
languages focus on declaring what a procedure (or function) should do rather than how it should do it. Classic examples of declarativeDeclarative languages focus on declaring what a procedure (or function) should do rather than how it should do it.
languages are SQL, HTML and Prolog.
- SQL precisely describes a relational database query (i.e. what should be returned) without having to tell the database how the computation should be performed (e.g. the sequence of steps to carry out to perform the query).
- HTML describes what a web page should look like without specifying how to render it. SQL and HTML both avoid defining the how by relying on an engine that already knows how to do the task (i.e. the database system (SQL) or the browser (HTML)).
- By contrast, Prolog is an example of a language that is declarativeDeclarative languages focus on declaring what a procedure (or function) should do rather than how it should do it. but also a complete programming language (being able to perform any computation that a Turing machineA model of computation based on a hypothetical machine reading or writing instructions on a tape, which decides how to proceed based on the symbols it reads from the tape. can compute, i.e. Turing Complete). DeclarativeDeclarative languages focus on declaring what a procedure (or function) should do rather than how it should do it. languages like Prolog manage to perform arbitrarily complex computations (e.g. with loops and evolving state) through recursive definitions.
- FunctionalFunctional languages are built around the concept of composable functions. Such languages support higher-order functions which can take other functions as arguments or return new functions as their result, following the rules of the Lambda Calculus. languages are built around the concept of composable functions. Such languages support higher-order functions which can take other functions as arguments or return new functions as their result, following the rules of the Lambda CalculusA model of computation based on mathematical functions proposed by Alonzo Church in the 1930s. (which we will explore in some depth later). FunctionalFunctional languages are built around the concept of composable functions. Such languages support higher-order functions which can take other functions as arguments or return new functions as their result, following the rules of the Lambda Calculus. languages such as Haskell (which we are going to explore later) adhere closely to the mathematical definition of functions that are pure, i.e. that do not have side effects but whose only result is an explicit return value. Pure functionalFunctional languages are built around the concept of composable functions. Such languages support higher-order functions which can take other functions as arguments or return new functions as their result, following the rules of the Lambda Calculus. programs tend to be closer to a declarativeDeclarative languages focus on declaring what a procedure (or function) should do rather than how it should do it. definition of the solution since their manipulation of state is made explicit from the function parameter and return types rather than hidden in side effects (this is a quality which we will see through many examples later). Many modern languages support a mixture of functionalFunctional languages are built around the concept of composable functions. Such languages support higher-order functions which can take other functions as arguments or return new functions as their result, following the rules of the Lambda Calculus. (i.e. by supporting higher-order functions) and imperativeImperative programs are a sequence of statements that change a program’s state. This is probably the dominant paradigm for programming languages today. Languages from Assembly to Python are built around this concept and most modern languages still allow you to program in this style. style programming (by allowing mutable variables and side effects from functions).
Until relatively recently, there was a fairly clear distinction between languages which followed the FunctionalFunctional languages are built around the concept of composable functions. Such languages support higher-order functions which can take other functions as arguments or return new functions as their result, following the rules of the Lambda Calculus. Programming (FP) paradigm versus the Object-OrientedObject-oriented languages are built around the concept of objects where an object captures the set of data (state) and behaviours (methods) associated with entities in the system. (OO) paradigm. From the 1990s to… well it still is… Object-OrientedObject-oriented languages are built around the concept of objects where an object captures the set of data (state) and behaviours (methods) associated with entities in the system. programming has been arguably the dominant paradigm. Programmers and system architects have found organising their programs and data into class hierarchies a natural way to model everything from simulations, to games, to business rules. But this focus on creating rigid structures around data is a static view of the world which becomes messy when dealing with dynamic state. FunctionalFunctional languages are built around the concept of composable functions. Such languages support higher-order functions which can take other functions as arguments or return new functions as their result, following the rules of the Lambda Calculus. programming, however, focuses on functions as transformations of data. These two alternatives, Object-OrientedObject-oriented languages are built around the concept of objects where an object captures the set of data (state) and behaviours (methods) associated with entities in the system. versus FunctionalFunctional languages are built around the concept of composable functions. Such languages support higher-order functions which can take other functions as arguments or return new functions as their result, following the rules of the Lambda Calculus. , have been described as a Kingdom of Nouns versus a Kingdom of Verbs, respectively, where nouns are descriptions of data and verbs are functions.
Historically these were seen as competing paradigms, leading to quite different languages such as C++ and Haskell. However, modern languages like TypeScript, Scala, C++17, Java >8, Swift, Rust, Python3 etc, provide facilities for both paradigms for you to use (or abuse) as you please.
Thus, these are no longer competing paradigms. Rather, they are complementary, or at least they can be depending on the skill of the programmer (we hope you come away with the skill to recognise the advantages of both paradigms). They provide programmers with a choice of abstractions to apply as necessary to better manage complexity and achieve robust, reusable, scalable and maintainable code.
Furthermore, the use of functionalFunctional languages are built around the concept of composable functions. Such languages support higher-order functions which can take other functions as arguments or return new functions as their result, following the rules of the Lambda Calculus. style code has become more commonplace throughout both industry and academia, and it is important you become literate in understanding this style of coding and how you can use it as a tool to make your code more robust.
These notes focus on introducing programmers who are familiar with the OO paradigm to FP concepts via the ubiquitous multiparadigm language of JavaScript. The following table functions as a summary and also an overview of the contents of these notes with links to relevant sections.
| FunctionalFunctional languages are built around the concept of composable functions. Such languages support higher-order functions which can take other functions as arguments or return new functions as their result, following the rules of the Lambda Calculus. | Object-OrientedObject-oriented languages are built around the concept of objects where an object captures the set of data (state) and behaviours (methods) associated with entities in the system. | |
|---|---|---|
| Unit of Composition | Functions | Objects (classes) |
| Programming Style | DeclarativeDeclarative languages focus on declaring what a procedure (or function) should do rather than how it should do it. | ImperativeImperative programs are a sequence of statements that change a program’s state. This is probably the dominant paradigm for programming languages today. Languages from Assembly to Python are built around this concept and most modern languages still allow you to program in this style. |
| Control Flow | Functions, recursion and chaining | Loops and conditionals |
| Polymorphism | Parametric | Sub-Typing |
| Data and Behaviour | Loosely coupled through pure, generic functions | Tightly coupled in classes with methods |
| State Management | Treats objects as immutable | Favours mutation of objects through instance methods |
| Thread Safety | Pure functions easily used concurrently | Can be difficult to manage |
| Encapsulation | Less essential | Needed to protect data integrity |
| Model of Computation | Lambda CalculusA model of computation based on mathematical functions proposed by Alonzo Church in the 1930s. | ImperativeImperative programs are a sequence of statements that change a program’s state. This is probably the dominant paradigm for programming languages today. Languages from Assembly to Python are built around this concept and most modern languages still allow you to program in this style. (von Neumann/Turing) |
Glossary
Syntax: The set of rules that defines the combinations of symbols that are considered to be correctly structured statements or expressions in a computer language.
Semantics: The processes a computer follows when executing a program in a given language.
Imperative: Imperative programs are a sequence of statements that change a program’s state. This is probably the dominant paradigm for programming languages today. Languages from Assembly to Python are built around this concept and most modern languages still allow you to program in this style.
Procedural: Procedural languages are basically imperative in nature, but add the concept of named procedures, i.e. named subroutines that may be invoked from elsewhere in the program, with parameterised variables that may be passed in.
Object-oriented: Object-oriented languages are built around the concept of objects where an object captures the set of data (state) and behaviours (methods) associated with entities in the system.
Declarative: Declarative languages focus on declaring what a procedure (or function) should do rather than how it should do it.
Functional: Functional languages are built around the concept of composable functions. Such languages support higher-order functions which can take other functions as arguments or return new functions as their result, following the rules of the Lambda Calculus.
Lambda Calculus: A model of computation based on mathematical functions proposed by Alonzo Church in the 1930s.
Turing Machine: A model of computation based on a hypothetical machine reading or writing instructions on a tape, which decides how to proceed based on the symbols it reads from the tape.
von Neumann model: A model of computation which is the basis for most modern computer architectures. Proposed by John von Neumann in 1945.